| 数仓回刷历史数据 | 您所在的位置:网站首页 › hive 用insert overwrite修改指定分区内的数据 › 数仓回刷历史数据 |
数仓回刷历史数据
|
数仓回刷历史数据–hive设置动态分区,并向动态分区内刷入历史数据
内容目录
数仓回刷历史数据--hive设置动态分区,并向动态分区内刷入历史数据一、问题介绍二、问题解决思路1 . 解决复杂逻辑任务2. 数据一致性3. 数据分区问题
三、必备知识1. checksum验证一致性2. hive动态分区
四、实际操作
一、问题介绍
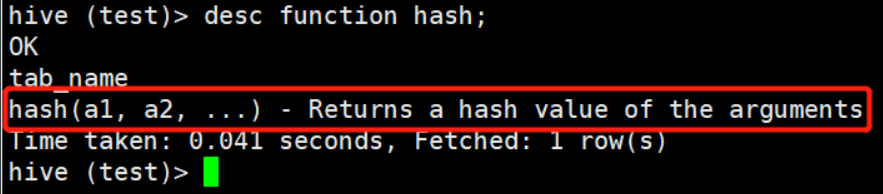
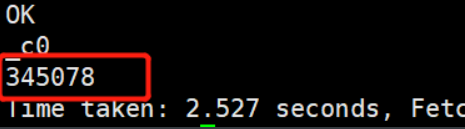
今天发现一张表在今年开始有一个字段就没有数据了,没有办法只能是去重新写下逻辑重新刷一下数据。 首先介绍一下这个表,是一张全量表,每天数据在3G左右,有多个上游任务,同时也有多个下游任务。所以对于刷数据的时候就哟啊考虑一下 刷数据有几个问题会出现: 原始逻辑很复杂,肯定不能通过直接重跑数据做到数据回刷刷数据怎么保证数据的一致性确实的数据有100天,如何把这些数据放到相应的分区,总不能运行100次吧 二、问题解决思路 1 . 解决复杂逻辑任务对于问题1,逻辑很复杂,上下游任务较多的时候,可以直接冲刷数据没有问题,但是不建议这样做,这里采取的办法是把确实的字段和表粒度信息放到一张临时表里,把数据全刷回临时表之后,再次把临时表数据刷到目标表即可 2. 数据一致性对于冲刷历史数据,最重要的肯定是数据怎么保证和已经入仓的数据保持一致性,如果辛辛苦苦刷了100天的数据,发现和仓里的数据完全对不上,那就面向白干式刷数据。 这里提供两种方案: ①比较简单的 看刷完数据和仓内数据某一天的数据行数,如果数据行数是一致的,那么可以80%的可能是没有问题的,但是也不排除20%的可能是有问题的。比如行数一致但是内容不一致。关于这个80%怎么来的,当然是我自己说的,没有科学依据 ②比较科学的 检查两张表的数据除了刷的字段之外的checksum是否相同。这类似于一种算法处理机制,可以类比一下码代码时候的equal方法,借助hash值把数据都搞在一起,看看是不是一致的,这种方法是比较科学的,因为java之父就是这样干的,如果非要鸡蛋里挑骨头,你可以说存在哈希碰撞的情况,可能会造成极其幸运情况下下的误差,那就说准确度99.9%吧 ③100%正确的 可以选择人工的把两张表数据拿出来,一个一个的去比较,当然也有你打盹眯眼的时候会出错 3. 数据分区问题对于100天的数据,就会去到100个分区里,对于一个调度项目,中规中矩的可以执行到一个分区,所以执行到100个分区内时,就要运行100次,如果一天数据刷10min,100次就是1000min,也就一天一夜加班加点就刷完了,你花了一天就刷了100天的数据,看似你亏了,实际上你赚了。你可以这样尝试一下 当然了,可以选择一个hive黑科技,动态分区,就能解放劳动力,指定一个分区字段,剩下的交给hive完成 三、必备知识理清了逻辑和分析了问题找到了解决方法,可能还需要一些必备知识 1. checksum验证一致性关于这个一致性验证,可以调用一个hash方法 这个方法会返回传进去参数的hash值 那么就可以直接 select sum(hash(column)) from tbl;
hive的动态分区在使用前需要先配置一下才行 ①开启动态分区参数 默认就是true hive.exec.dynamic.parition=true②设置非严格模式 注意,必须设置非严格模式,否则不行 hive.exec.dynamic.parition.mode=nonstrict③所有节点最大动态分区个数 hive.exec.max.dynamic.paritions=1000④每个节点最大动态分区个数 hive.exec.max.dynamic.partitions.pernode=100⑤整个mr job种可以创建多少HDFS文件 hive.exec.max.created.files=100000以上这些不走就时配置好了动态分区 四、实际操作这里做一个测试,并不是真实的数据 首先创建一张分区表 create table dyntable(name string, job int) partitioned by (logdate int);看一下我们的表信息 desc extended dyntable;
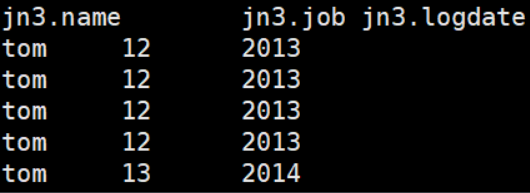
我们拿两张表的数据简单连接一下往动态分区内刷数据 insert into table dyntable partition (logdate) select j1.name ,j1.job ,j2.logdate from jn1 j1 left join jn2 j2 on j1.name=j2.name and j1.logdate=j2.logdate;这里有一个注意点,分区数据要在select字段的最后一个,因为会把前面的字段放进表字段内 查看刷进去的数据 select * from dyntable;
|

【本文地址】